Abstract
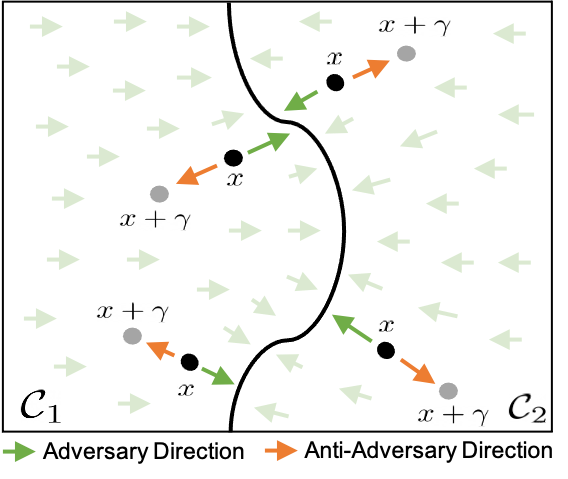
Deep neural networks are vulnerable to small input perturbations known as adversarial attacks. Inspired by the fact that these adversaries are constructed by iteratively minimizing the confidence of a network for the true class label, we propose the anti-adversary layer, aimed at countering this effect. In particular, our layer generates an input perturbation in the opposite direction of the adversarial one, and feeds the classifier a perturbed version of the input. Our approach is training-free and theoretically supported. We verify the effectiveness of our approach by combining our layer with both nominally and robustly trained models, and conduct large scale experiments from black-box to adaptive attacks on CIFAR10, CIFAR100 and ImageNet. Our anti-adversary layer significantly enhances model robustness while coming at no cost on clean accuracy.
Motasem Alfarra
Machine Learning Researcher at Qualcomm AI Research, Amsterdam, Netherlands
I am a research scientist at Qualcomm AI Research in Amsterdam, Netherlands. I obtained my Ph.D. in Electrical and Computer Engineering from KAUST in Saudi Arabia advised by Prof. Bernard Ghanem. I also obtained my M.Sc degree in Electrical Engineering from KAUST, and my undergraduate degree in Electrical Engineering from Kuwait University. I am interested in domain shifts, LLM safety, and how to combat them with test-time adaptation and continual learning. I helped co-organizing the first and second workshops on Test-Time Adaptation at CVPR2024 and ICML2025 and the ICLR2026 workshop on Monitoring ML Models Under Drift.