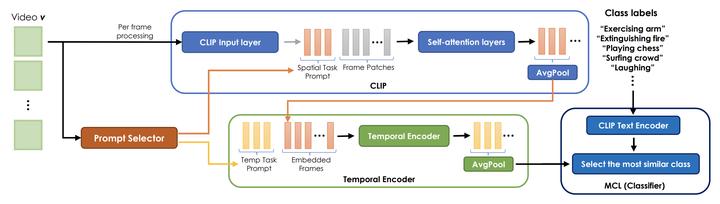
Abstract
Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.
Motasem Alfarra
Machine Learning Researcher at Qualcomm AI Research, Amsterdam, Netherlands
I am a research scientist at Qualcomm AI Research in Amsterdam, Netherlands. I obtained my Ph.D. in Electrical and Computer Engineering from KAUST in Saudi Arabia advised by Prof. Bernard Ghanem. I also obtained my M.Sc degree in Electrical Engineering from KAUST, and my undergraduate degree in Electrical Engineering from Kuwait University. I am interested in domain shifts, LLM safety, and how to combat them with test-time adaptation and continual learning. I helped co-organizing the first and second workshops on Test-Time Adaptation at CVPR2024 and ICML2025 and the ICLR2026 workshop on Monitoring ML Models Under Drift.