Abstract
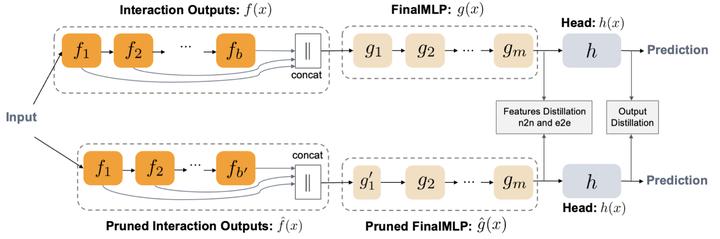
Advancements in machine learning for molecular property prediction have improved accuracy but at the expense of higher computational cost and longer training times. Recently, the Joint Multi-domain Pre-training (JMP) foundation model has demonstrated strong performance across various downstream tasks with reduced training time over previous models. Despite JMP’s advantages, finetuning it on molecular datasets ranging from small-scale to large-scale requires considerable time and computational resources. In this work, we investigate strategies to enhance efficiency by reducing model size while preserving performance. To better understand the model’s efficiency, we analyze the layer contributions of JMP and find that later interaction blocks provide diminishing returns, suggesting an opportunity for model compression. We explore block reduction strategies by pruning the pre-trained model and evaluating its impact on efficiency and accuracy during fine-tuning. Our analysis reveals that removing two interaction blocks results in a minimal performance drop, reducing the model size by 32% while increasing inference throughput by 1.3 x. These results suggest that JMP-L is over-parameterized and that a smaller, more efficient variant can achieve comparable performance with lower computational cost. Our study provides insights for developing lighter, faster, and more scalable foundation models for molecular and materials discovery.
Motasem Alfarra
Machine Learning Researcher at Qualcomm AI Research, Amsterdam, Netherlands
I am a research scientist at Qualcomm AI Research in Amsterdam, Netherlands. I obtained my Ph.D. in Electrical and Computer Engineering from KAUST in Saudi Arabia advised by Prof. Bernard Ghanem. I also obtained my M.Sc degree in Electrical Engineering from KAUST, and my undergraduate degree in Electrical Engineering from Kuwait University. I am interested in domain shifts, LLM safety, and how to combat them with test-time adaptation and continual learning. I helped co-organizing the first and second workshops on Test-Time Adaptation at CVPR2024 and ICML2025 and the ICLR2026 workshop on Monitoring ML Models Under Drift.